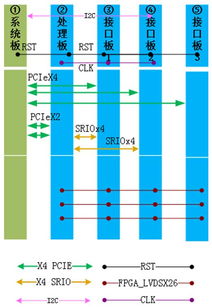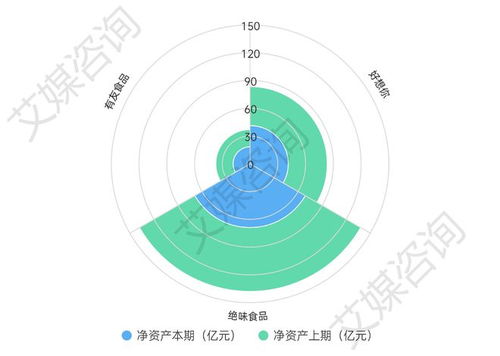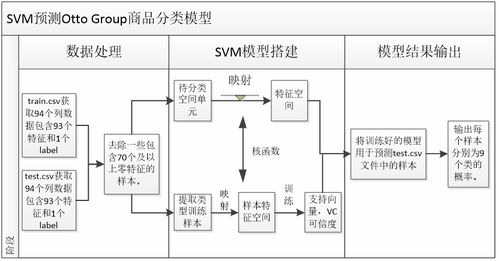
在零售和電商領域,商品識別是優化用戶體驗、提升推薦系統準確性的核心技術之一。Otto Group作為全球領先的電商企業,其公開的商品識別數據集為研究和實踐提供了寶貴資源。本文旨在詳細闡述如何利用Python對Otto Group商品數據進行系統化的數據處理,為后續的識別模型構建奠定堅實基礎。
一、數據理解與加載
Otto Group商品識別數據集通常包含大量商品條目,每條記錄由商品ID、多個特征屬性(如商品類別、品牌、顏色、材質等)以及目標分類標簽組成。數據格式常為CSV或JSON。我們首先使用Pandas庫進行加載與初步探索。
`python
import pandas as pd
import numpy as np
加載數據集
data = pd.readcsv('ottoproduct_data.csv')
print(f"數據形狀: {data.shape}")
print(data.head())
print(data.info())`
通過describe()和value_counts()方法,我們可以快速了解數值特征的分布與類別特征的取值情況,識別潛在的缺失值與異常值。
二、數據清洗
高質量的數據是模型成功的基石。清洗步驟主要包括:
- 處理缺失值:對于少量缺失,可采用眾數、中位數或基于其他特征的預測進行填充;若缺失嚴重,則考慮刪除該特征或樣本。
- 處理異常值:通過箱線圖或標準差方法檢測并處理異常數值,避免其對模型產生干擾。
- 格式統一:確保文本類特征(如品牌名)的大小寫、空格一致,避免因格式問題導致識別錯誤。
`python
# 示例:填充缺失值
data['color'].fillna(data['color'].mode()[0], inplace=True)
示例:處理異常值(假設'price'為數值特征)
Q1 = data['price'].quantile(0.25)
Q3 = data['price'].quantile(0.75)
IQR = Q3 - Q1
data = data[~((data['price'] < (Q1 - 1.5 IQR)) | (data['price'] > (Q3 + 1.5 IQR)))]`
三、特征工程
特征工程是提升模型性能的關鍵環節,旨在從原始數據中提取更有信息量的特征。
- 特征編碼:將類別特征(如商品類別、品牌)轉換為數值形式。常用方法包括標簽編碼(Label Encoding)和獨熱編碼(One-Hot Encoding)。對于高基數類別,可考慮目標編碼(Target Encoding)或嵌入(Embedding)。
- 特征構造:基于領域知識,組合或衍生新特征。例如,從商品描述中提取關鍵詞,或計算價格與平均價格的比值等。
- 特征縮放:對于基于距離的模型(如KNN、SVM),需對數值特征進行標準化(StandardScaler)或歸一化(MinMaxScaler),使其處于相近的量綱。
`python
from sklearn.preprocessing import LabelEncoder, OneHotEncoder, StandardScaler
標簽編碼示例
le = LabelEncoder()
data['categoryencoded'] = le.fittransform(data['category'])
獨熱編碼示例(需謹慎處理高維特征)
data = pd.get_dummies(data, columns=['brand'], prefix='brand')
標準化示例
scaler = StandardScaler()
data[['price', 'weight']] = scaler.fit_transform(data[['price', 'weight']])`
四、數據分割
為避免過擬合,需將數據劃分為訓練集、驗證集和測試集。通常按比例(如70%-15%-15%)隨機分割,并確保類別分布均衡(可使用分層抽樣)。
`python
from sklearn.modelselection import traintest_split
假設X為特征,y為目標標簽
X = data.drop('targetclass', axis=1)
y = data['targetclass']
Xtrain, Xtemp, ytrain, ytemp = traintestsplit(X, y, testsize=0.3, stratify=y, randomstate=42)
Xval, Xtest, yval, ytest = traintestsplit(Xtemp, ytemp, testsize=0.5, stratify=ytemp, random_state=42)`
五、處理不平衡數據
商品識別數據集中,各類別商品的數量可能存在嚴重不平衡。為提升少數類的識別效果,可采用以下方法:
- 重采樣:過采樣少數類(如SMOTE算法)或欠采樣多數類。
- 調整類別權重:在模型訓練時,為少數類賦予更高的損失權重。
六、數據存儲與管道化
處理完成的數據應妥善存儲,如保存為新的CSV文件或Feather格式以供后續快速讀取。可將整個預處理流程封裝為Pipeline,確保訓練與預測時數據處理的一致性。
`python
# 保存處理后的數據
data.tocsv('processedotto_data.csv', index=False)
使用Pipeline示例(需結合具體轉換器)
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
pipeline = Pipeline([
('imputer', SimpleImputer(strategy='most_frequent')),
('scaler', StandardScaler())
])`
###
通過以上系統化的數據處理流程,我們能夠將原始的Otto Group商品數據轉化為干凈、規整、富含信息的特征集合。這為后續應用機器學習模型(如梯度提升樹、神經網絡)進行精準的商品識別奠定了堅實基礎。數據處理并非一蹴而就,需根據模型反饋與實際業務需求不斷迭代優化,方能實現最佳識別效果。